Web scraping has many uses for good and bad. Companies can use it to enhance the security and reliability of their public facing websites. Another use would be to scrape all incoming and outgoing email traffic to check for sensitive data or specific attacks like phishing attempts and various forms of financial fraud. Bad actors can use web scraping scripts to check for vulnerabilities in an organization’s website, which could let them access data they shouldn’t be able to, or set up attacks to overload their web servers. The possibilities for web scraping don’t end with these few examples but they serve to give an idea of what is possible.
#!/usr/bin/python3
# scrape the names of the 100 projects from Replit
import requests
from bs4 import BeautifulSoup
import csv
#make request
page = requests.get('https://replit.com/learn/100-days-of-python')
soup = BeautifulSoup(page.content, 'html.parser')
#create all_titles as empty list
all_titles = []
#extract and store in all_titles according to instructions on the left
titles = soup.select('div.css-7rldpb')
for title in titles:
day = title.select('span')[0].text.strip()
project = title.select('p')[0].text.strip()
all_titles.append({
"Day": day,
"Project": project
})
keys = all_titles[0].keys()
with open('replit.csv', 'w', newline='') as output_file:
dict_writer = csv.DictWriter(output_file, keys)
dict_writer.writeheader()
dict_writer.writerows(all_titles)
This script will go over a simple example of how we can scrape some data from a website. The great thing about it is that it can be modified to fit the needs of whatever you are trying to do. We will start by visiting the Replit 100 Days of Python website, which is itself a great tool to begin learning how to code with Python. https://replit.com/learn/100-days-of-python

On this page you can scroll down and find their course preview which has 100 projects to complete over 100 days. This portion of the page is designed to be interactive and the user is unable to highlight the text for each day in a simple way. Well for our purposes we want to be able to collect all these project titles and their corresponding days and store that information in a spreadsheet. The preceding code will allow us to do this quite easily.
#!/usr/bin/python3
# scrape the names of the 100 projects from ReplitThis first line is the shebang, which tells this Linux system which interpreter to use for running the script. The second line just explains the purpose of the script.
import requestsThis line imports the Requests module which is not a built-in Python module. It will allow us to send HTTP requests using Python.
from bs4 import BeautifulSoupThis line imports BeautifulSoup which is a library that allows us to easily scrape information from web pages. It has to be installed to be used with Python.
import csvThis line imports the built-in CSV module for working with CSV format. It will be used at the end of the script to add the collected data to spreadsheet.
page = requests.get('https://replit.com/learn/100-days-of-python')This line sends a Get request to the URL within the parentheses and returns a response object with all the response data, including encoding, status, content, etc.
soup = BeautifulSoup(page.content, 'html.parser')This line feeds the content of the page into BeautifulSoup and allows us to parse the HTML. This is one of the great things about Python, there is usually already a library written for so many functions that saves you time from not having to write your own complex code.
all_titles = []This line creates a new empty list with the name all_titles. We will store the data that we scrape from the website here.
titles = soup.select('div.css-7rldpb')This line takes the ‘page.content’ that we sent to BeautifulSoup a couple lines previously and allows us to parse the DOM tree of the webpage. We will use the Select function of BeautifulSoup and set it to the appropriate object which contains the portion of the webpage we want to scrape. We will set the variable ‘titles’ to this.
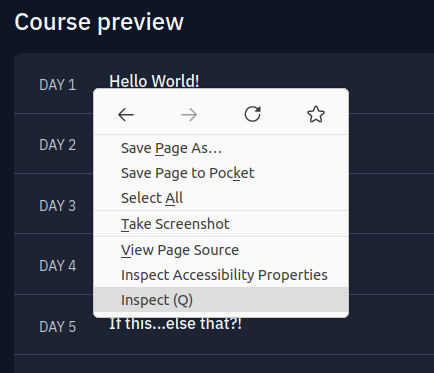
In order to figure out what to use, you can do so by navigating to the relevant portion of the webpage and right click on the element you want to scrape. You should see an option to ‘Inspect’ which will open up the Inspector where you can see the HTML that makes up the webpage. To figure out what do with all this code, you can hover the mouse over each line and it will highlight on the displayed webpage the element that the line pertains to.
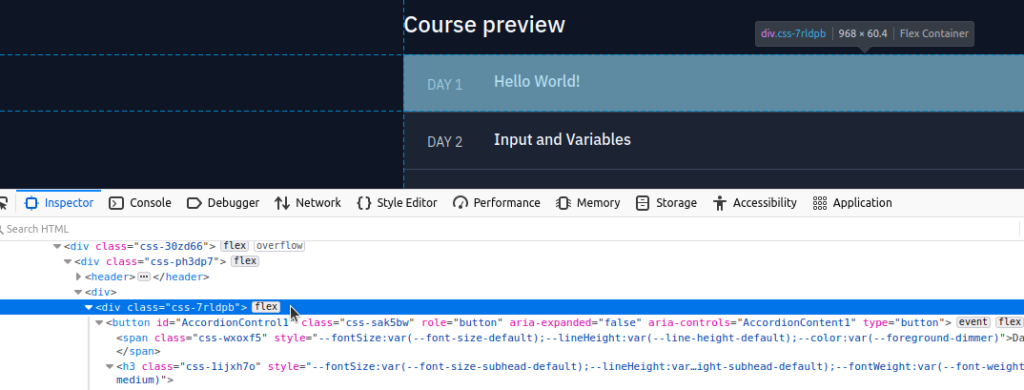
In this case we can see that this particular line corresponds to the page element that contains the data we want. We will copy the object type ‘div’ and the class which is defined as ‘css-7rldpb’ and use this in our Python script. You’ll also notice that this same class applies to all 100 days.
for title in titles:This line sets up a ‘for’ loop, which will allow us to loop through all 100 instances of the ‘div – class’ combo we set up previously.
day = title.select('span')[0].text.strip()
project = title.select('p')[0].text.strip()These next two lines will set the respective day and project name to the variables ‘day’ and ‘project.’ We’ll have to go back to the Inspector to find the appropriate tags so that BeautifulSoup knows where to find the data we want.
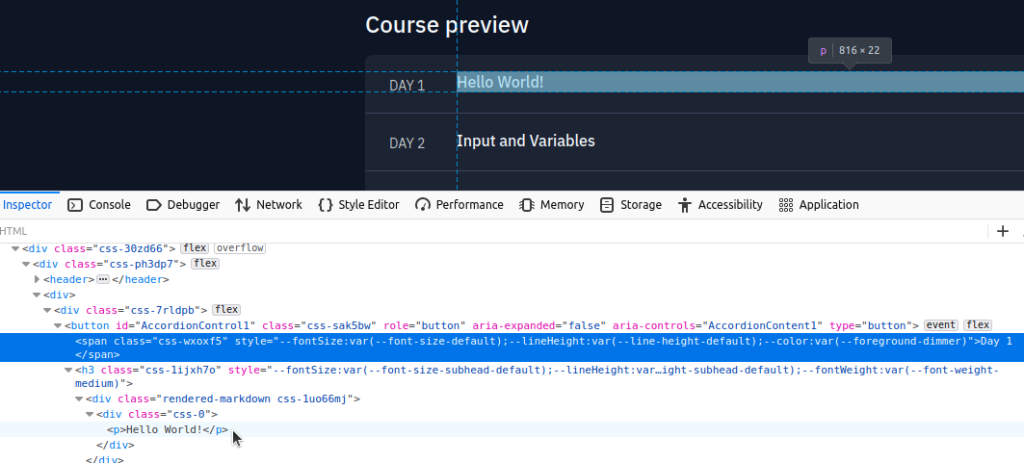
You’ll notice again when hovering over the lines that the tags ‘span’ and ‘p’ contain the actual text that we want to collect. The brackets signify to store the text of the first ‘span’ and ‘p’ elements. Remember that with lists, ‘0’ equates to the first instance of something, and in this case we want that first instance of text. We finish off with the ‘strip’ method which will remove any extra new lines or white space that are part of the output.
all_titles.append({
"Day": day,
"Project": project
})These next few lines will create a dictionary which we will append to the list ‘all_titles’ which we created earlier. We will create the key:value pairs for ‘Day’ and ‘Project’ and for every time we loop through the For loop the variables ‘day’ and ‘project’ will be appended to this dictionary using the Append function.
keys = all_titles[0].keys()This line creates the ‘keys’ variable and sets it to the value of the first object within the ‘all_titles’ list. That first object is the dictionary we created and we have used the ‘keys’ method on it to return all of the keys within the dictionary in a list. The keys in the dictionary are the first part of the key:value pairs within it, and in this case would be ‘Day’ and ‘Project.’
with open('replit.csv', 'w', newline='') as output_file:This line will create our csv file. The ‘With’ statement used with the ‘open’ function will open a file that we can then manipulate. We will pass a few arguments to the ‘open’ function and up first is the name of the new csv file. After that we want to open it in ‘Write’ mode so that we can pass the data to it. Lastly we use the argument ‘newline=’’’ which will prevent blank rows from being placed between the data. The end of the line we use ‘as’ to set the previous code to the variable named ‘output_file.’
dict_writer = csv.DictWriter(output_file, keys)This line creates a new instance of the DictWriter class from the csv module and we will pass the file object (output_file) and ‘keys’ variable as arguments to it.
dict_writer.writeheader()This line creates the header of the csv file by calling the ‘writeheader’ function.
dict_writer.writerows(all_titles)This line will write all the data rows to the csv file by using the ‘writerows’ function and passing in our dictionary ‘all_titles’ as an argument to it.
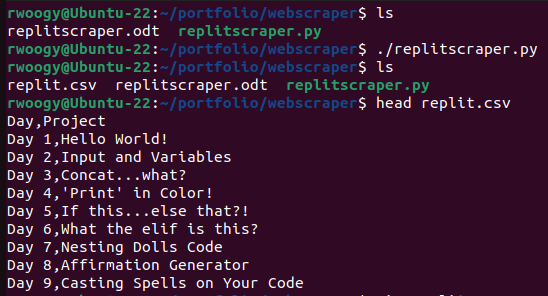
With the code complete we can now check if it works. We can check the directory contents before running the script from the command line. Then we run the script by typing ./scritp_name.py and hitting enter from the command line. Listing the directory contents again will show that the new csv file has been created, and we can used the ‘head’ command to check the first ten lines to see that it worked.
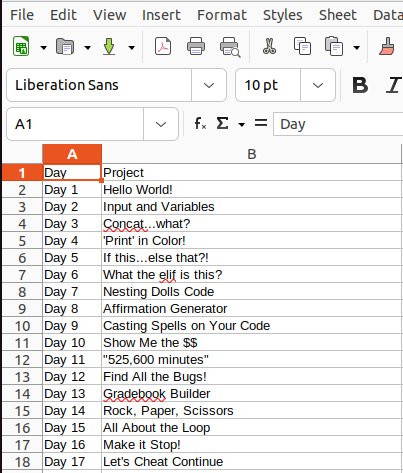
We can also check with a spreadsheet software to see how it will appear there. It was able to scrape the website and collect all the data we required and write it to this csv file.

